
Mesmo com o crescimento dos NoSQL, os bancos de dados relacionais ainda são os mais populares entre os usuários.
O relacionamento um para muitos (também chamado de 1 para N, 1:N ou one-to-many) é provavelmente o tipo mais comum que você vai se deparar quando estiver trabalhando com tabelas em bancos de dados do modelo relacional.
Neste artigo eu discuto um pouco sobre o que é e como pensar a implementação de relações one-to-many.
Pare um tempo para pensar
Primeiro de tudo, é importante gastar um tempo refletindo sobre o tipo de relação que os elementos das tabelas guardam entre si na vida real.
Às vezes é fácil identificar de cara o tipo de relação que duas entidades mantêm, mas é sempre útil investir um pouquinho do nosso tempo para tentar as encontrar.
Nas associações do tipo um para muitos temos uma entidade (a qual eu vou chamar de “mãe”) que se relaciona com várias entidades (“filhas”) ao mesmo tempo.
Enquanto uma mãe pode ter várias filhas, uma filha pode ter apenas uma única mãe. Em essência, é disso que se trata as relações de um para muitos.
Visualizando
Aproveitando que, enquanto escrevo este texto, está acontecendo a Copa do Mundo FIFA de 2022, vamos pensar em um exemplo futebolístico.
Supondo que temos à nossa disposição um banco de dados com duas tabelas:
- na primeira, temos a relação dos atletas convocados para a Copa;
- na segunda, estão listados os gols marcados até a fase de oitavas de final.
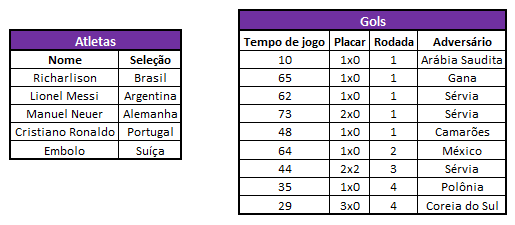
Nossos dados, do jeito que estão, não mostram nenhum tipo de relação, sendo apenas duas tabelas separadas. Agora é hora de nos perguntarmos: qual tipo de relação observamos e que queremos implementar?
Bem, neste caso, quero que cada gol esteja associado ao jogador que o marcou e, logicamente, cada atleta estará associado aos seus respectivos gols.
Podemos, então, assinalar os atletas e os gols com um identificador. Aqui eu escolhi associá-los por cores, mas não se preocupe muito com isso, mais à frente vamos expandir essa ideia.
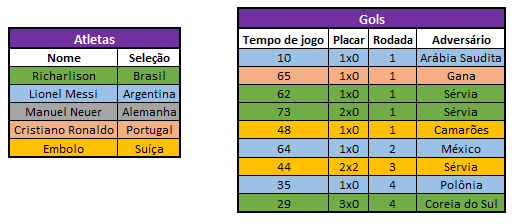
Sabemos que um jogador pode marcar mais de um gol (se não fosse assim não existiriam os artilheiros), mas que um gol específico só pode ser anotado por um único atleta (mesmo que seja um gol contra). E nem todo jogador precisa marcar um gol, também. É o caso do atleta Manuel Neuer, que é goleiro.
Uma relação um para muitos não significa que toda entidade mãe precisa estar associada a muitas entidades filhas. Mas que essa associação é possível.
Assim, podemos afirmar que a relação “atletas-gols” é uma relação do tipo um para muitos. Bem, agora é hora de implementar a lógica dessa associação no banco de dados.
As chaves primária e estrangeira
Agora que já podemos enxergar qual atleta marcou quais gols é hora de passar isso para o computador.
Cada jogador corresponde a uma única entrada na tabela “Atletas” (uma observação ou ponto de dados). Já cada gol também corresponde a um único ponto de dados, mas na tabela “Gols”.
Para que o computador entenda quem deve ficar com quem nas tabelas, precisamos atribuir dois tipos de chaves:
- uma chave primária para aqueles dados que não se repetem (no nosso caso, cada atleta); e
- uma chave estrangeira para os dados que serão relacionados àqueles primeiros (cada gol).
As chaves primárias precisam ser exclusivas, isto é, cada uma delas deve estar atribuída a uma única entrada. Se não fosse assim, não seria possível saber quais entidades estão relacionadas entre si (qual jogador fez qual gol).
Em nosso exemplo as cores funcionariam como as chaves. Note que cada jogador tem uma cor única, mas uma mesma cor pode se repetir para gols diferentes.
Adicionando as chaves ao nosso banco de dados
Bem, os bancos de dados relacionais não aceitam cores como chaves primárias e estrangeiras – além disso, seria muito difícil conseguir cores diferentes para milhões de dados. Por isso, precisamos atribuir valores a elas.
Para isso, adicionamos uma coluna chamada “id” na tabela “Atletas”. É um identificador exclusivo para cada jogador.
Já na tabela “Gols” colocamos uma coluna “Marcador”. O valor associado a essa coluna é exatamente o “id” do atleta que anotou o respectivo gol.
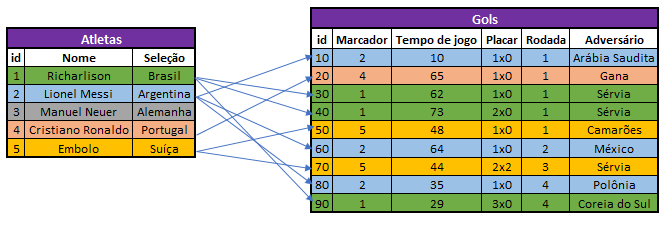
Assim, a coluna “id” em “Atletas” é nossa chave primária e a coluna “Marcador” em “Gols” é nossa chave estrangeira.
Você deve ter percebido que eu também adicionei uma coluna “id” na tabela Gols. Os valores dessa coluna também são chaves primárias, mas para especificar cada gol.
Por mais que isso não seja necessário para a relação “atleta-gols”, é uma boa prática atribuir chaves primárias (identificadores únicos) para todas as entidades. Afinal, podemos precisar fazer outras relações no futuro, e essas chaves vão nos ajudar com isso.
No fim…
Agora você já entendeu o que é um relacionamento do tipo um para muitos e como representá-los em bancos de dados relacionais.
Recapitulando:
- uma relação um para muitos significa que uma entidade se relaciona a várias outras, e que estas outras só podem se relacionar com aquela entidade em específico (uma mãe pode ter várias filhas, mas cada filha só tem uma mãe);
- usamos as chaves primárias e chaves estrangeiras para representar os relacionamentos;
- uma chave primária precisa ser única, não pode se repetir, já as chaves estrangeiras podem (e muito provavelmente vão) se repetir.
É isso. Obrigado por ter lido até aqui e fique à vontade para deixar o seu comentário abaixo.
Bons negócios!

Deixe um comentário